GPT 5.4
GPT-5.4 具备强大多步骤推理能力与高质量代码生成能力,支持AI Agent自动化与跨应用操作,并提供最高100万token长上下文处理以及Mini和Nano多版本模型以满足不同性能与成本需求。
自动附加历史消息以保持多轮对话上下文,可能会增加 Token 消耗。
用于提供上下文和指令,引导 AI 在整个对话中的行为
控制随机性:0 = 更稳定,2 = 更有创造力
响应的最大长度
最大完成令牌数(优先于 max_tokens)
核采样:0.1 = 更稳定,1.0 = 更多样
减少重复:-2.0 到 2.0
减少重复内容:范围 -2.0 到 2.0
在可用时显示 AI 的推理过程
暂无消息。开始对话吧!
GPT-5.4:真正为专业工作而生的模型
它更擅长处理高要求任务,输出更稳,工具能力更强,也能减少反复沟通和返工。
面向真实工作的核心能力
它不是只负责“说得好听”,而是更偏向把复杂任务真正做完。
更稳的专业输出
面对文档、表格、演示文稿这类真实工作,它更强调可用性和稳定性,而不只是表面好看。
运行中可调整方向
GPT-5.4 Thinking 会先给出思路,你可以在任务还没结束时调整方向。
更强的长任务保持力
在长任务里,它更能抓住上下文,不容易跑偏,尤其适合步骤多、周期长的工作。
原生计算机使用
它原生支持计算机使用,能看屏幕、理解截图,并通过鼠标和键盘动作完成操作。
更会找工具、也更会用工具
它能在复杂工具生态里更快找到合适工具,让流程更顺,不必反复试错。
更省 token,也更快
它是目前 token 效率最高的推理模型之一,很多任务会更省 token,响应也更快。
面向真实工作流程的能力设计
GPT-5.4 围绕实际工作场景构建,无论是文档处理、工具协同,还是复杂多步骤任务,都更强调结果的可用性、稳定性以及接近成品的输出质量。
更适合需要“拿得出手”的知识型工作
GPT-5.4 的强项,不只是把内容写出来,而是把内容写得更像一个完整成品。无论是文档、表格,还是演示文稿,它都更强调结构、清晰度和整体完成度。对很多专业场景来说,真正耗时间的往往不是“生成”,而是“改到能用”。GPT-5.4 的目标,就是尽量把可用结果直接推到前面。
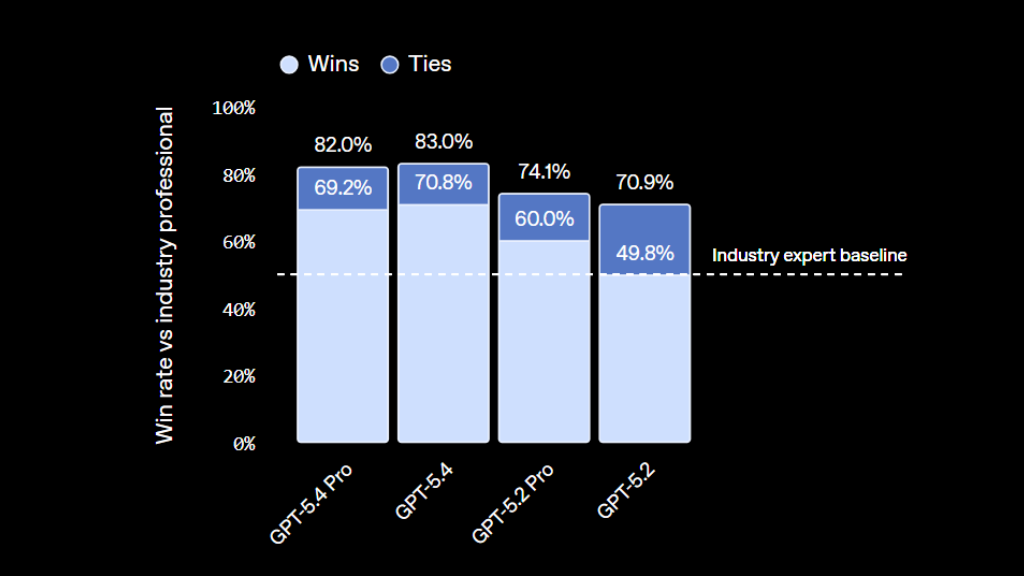
真正能看屏幕、会操作的模型
GPT-5.4 最大的变化之一,就是它原生支持计算机使用能力。它不只是读文字,而是能够看懂屏幕内容、理解截图,并通过鼠标和键盘动作去完成实际操作。这样一来,那些需要在浏览器、桌面软件和表单之间来回切换的流程,就更适合交给它处理。官方还特别强调了它更强的视觉理解能力,这会让它在处理界面、截图和文档时更稳定。
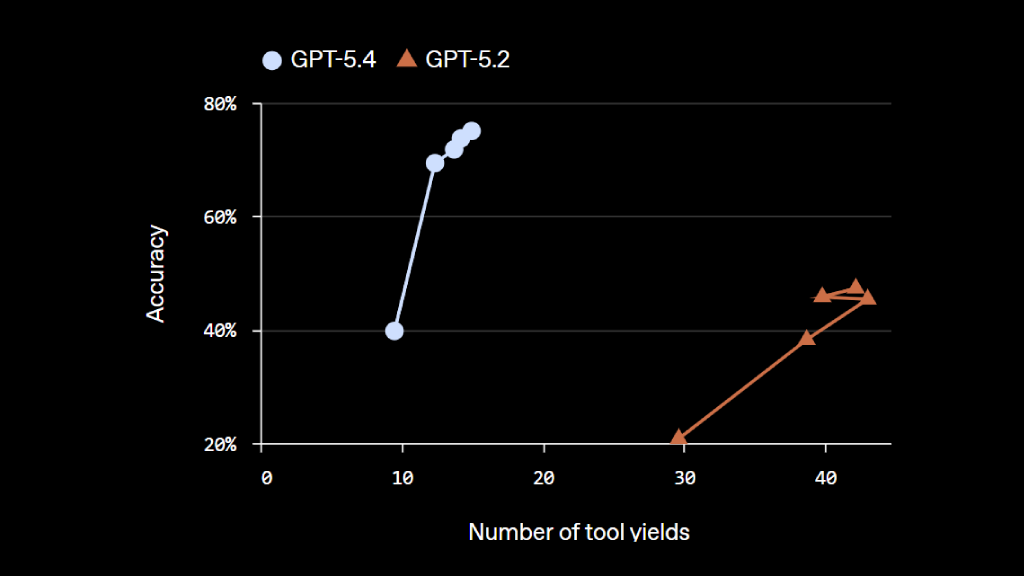
更适合编码和长流程任务
GPT-5.4 把编程能力保留下来,同时又加强了工具使用和复杂任务处理能力。它特别适合那些不是“一问一答就结束”的工作,而是需要反复迭代、验证、继续推进的长流程任务。对于开发者、智能体系统和自动化流程来说,这种能力很实用,因为它更像一个能持续推进工作的协作者,而不是只给一次性回答的工具。
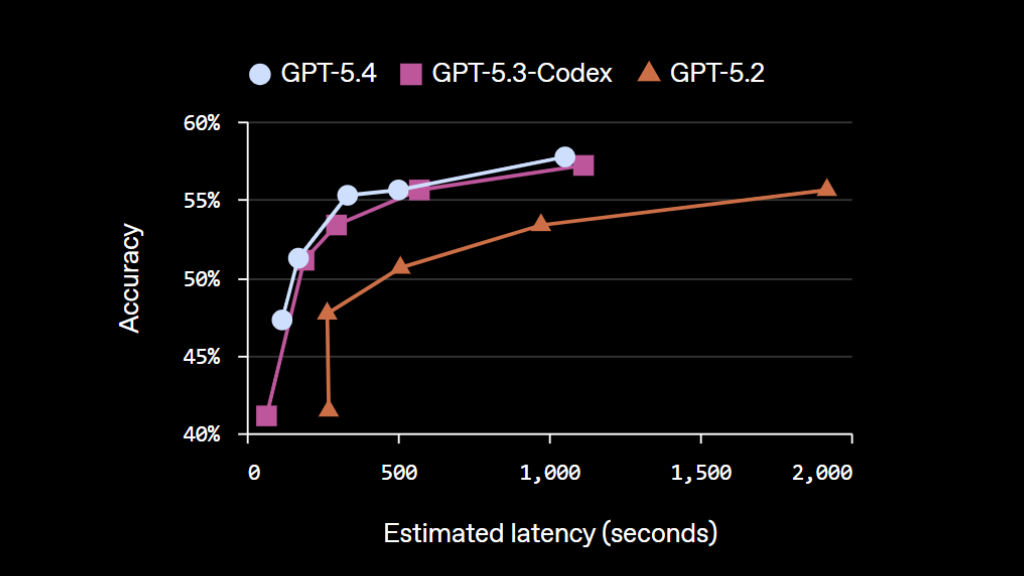
GPT-5.4 vs Gemini 3.1 Pro vs Claude Sonnet 4.6 对比
与其问“哪个更强”,不如看哪个更适合你的工作方式。这三个模型的方向其实非常不一样。
| 对比维度 | GPT-5.4 | Gemini 3.1 Pro | Claude Sonnet 4.6 |
|---|---|---|---|
模型定位 | 专业工作模型 | 高级推理模型 | 长上下文与稳定模型 |
核心优势 | 工具调用 + 电脑操作 | 深度推理 + 大规模数据理解 | 长上下文 + 稳定性 |
最适合 | 文档、表格、自动化、智能体 | 数学、研究、复杂推理 | 长文档、写作、规划 |
工具能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
电脑操作 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
编码能力 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
长上下文 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
速度 / 效率 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
短板 | 单 token 成本略高 | 工作流能力较弱 | 自动化能力偏弱 |
GPT 5.4 常见问题
GPT-5.4 是什么?
它是 OpenAI 面向专业工作的前沿模型,重点适合长流程任务、工具调用和稳定执行。GPT-5.4 和 GPT-5.2 有什么不同?
GPT-5.4 更强调知识型工作、计算机使用和工具密集型流程。GPT-5.4 适合编程吗?
适合。官方强调它在编程和复杂长任务上的表现更强。GPT-5.4 能操作电脑吗?
可以。官方提到它在需要截图、鼠标动作和键盘操作的计算机使用任务上表现很强。GPT-5.4 最适合做什么?
它适合文档、表格、演示文稿、自动化、智能体和其他专业工作流。
